
Projects
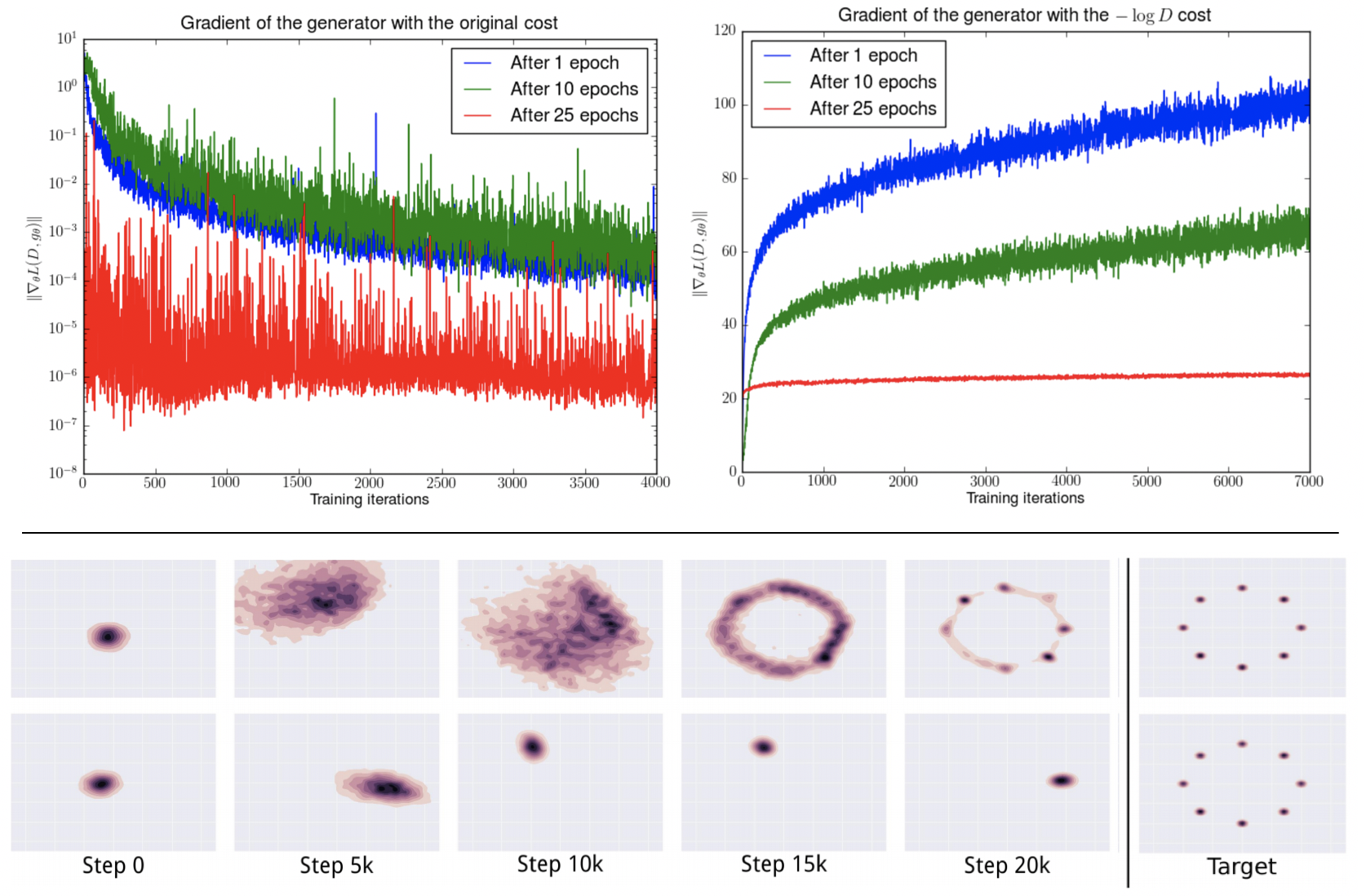
Stabilising Generative Adversarial Network Training
Generative Adversarial Networks (GANs) are a type of Generative Models, which received wide attention for their ability to model complex real-world data. With a considerably large number of potential applications and a promise to alleviate some of the major issues of the field of Artificial Intelligence, recent years have seen rapid progress in the field of GANs. Despite the relative success, the process of training GANs remains challenging, suffering from instability issues such as mode collapse and vanishing gradients. This project aims at reviewing currently employed approaches and methods for the purpose of stabilizing GAN training procedure, as well as developing new ones drawing on methods from multi-agent learning.
Governing the commons with Multi-Agent Reinforcement Learning
In the natural environment, groups of individuals are often faced with the problem of governing common-pool resources. Various studies have shown that stable local communities with limited influence of external forces in fact managed to sustain common resources such as fisheries, irrigation systems or grazing pastures over centuries. Nevertheless, the challenge arises when the problem is on a global scale. This work proposes a multi-agent reinforcement learning framework, allowing for the meticulous observation of the emergent behavior of the agents in the game mimicking the tragedy of the commons paradigm. Employing deep multi-agent reinforcement learning, we show how, through trial-and-error the artificial agents learn to sustainably govern the commons in a single-, two- and multi-agent setting. The general-sum Markov game created for the purpose of the project mimics the common-pool resource appropriation problem enabling for flexible manipulation of agents’ and environment’s parameters. The experiments conducted by deploying independently learning agents in a number of specifically designed environments provide detailed insights on the range of emergent social outcomes and show that advanced human-like cognitive capabilities are not necessarily required for sustainable resource management.

Sequential Social Dilemma (SSDs) environments for Multi-Agent Reinforcement Learning
Social dilemmas are widely used for the purpose of research on cooperation in game theory, behavioural economics, and recently, artificial intelligence. Proposed as an alternative to matrix games like Prisoner’s Dilemma which tend to treat actions as atomic, social dilemmas capture the crucial temporal and spatial aspects of the behaviour of the agents when faced with a decision exposing tension between collective and individual rationality. Therefore, making it possible to analyse the dynamics of the learning agents powered by deep reinforcement learning algorithms. This project aims at recreating, improving and finally open-sourcing the sequential social dilemma game environments proposed in recent publications for research purposes.



MyBikeSafetyNet [OxfordHACK 2018]
App visualizing bike theft data acquired from data.police.uk/data/ to help in identifying localizations, where bikes are more likely to be stolen. Build as a project for OxfordHACK 2018.